Variance
Chebyshev’s Inequality
Problem: Estimating the Bias of a Coin
Suppose we have a biased coin, but we don’t know what the bias is. To estimate the bias, we toss the coin \(n\) times and count how many Heads we observe. Then our estimate of the bias is given by \(\hat p = S_n/n\), where \(S_n\) is the number of Heads in the \(n\) tosses. Is this a good estimate? Let \(p\) denote the true bias of the coin, which is unknown to us. Since \({\mathbb{E}}[S_n] = np\), we see that the estimator \(\hat p\) has the correct expected value: \({\mathbb{E}}[{\hat p}] = {\mathbb{E}}[S_n]/n = p\). This means when \(n\) is sufficiently large, we can expect \(\hat p\) to be very close to \(p\); this is a manifestation of the Law of Large Numbers, which we shall see at the end of this note.
How large should \(n\) be to guarantee that our estimate \(\hat p\) is within an error \(\epsilon\) of the true bias \(p\), i.e., \(|\hat p - p| \le \epsilon\)? The answer is that we can never guarantee with absolute certainty that \(|\hat p - p| \le \epsilon\). This is because \(S_n\) is a random variable that can take any integer values between \(0\) and \(n\), and thus \(\hat p = S_n/n\) is also a random variable that can take any values between \(0\) and \(1\). So regardless of the value of the true bias \(p \in (0,1)\), it is possible that in our experiment of \(n\) coin tosses we observe \(n\) Heads (this happens with probability \(p^n\)), in which case \(S_n = n\) and \(\hat p = 1\). Similarly, it is also possible that all \(n\) coin tosses come up Tails (this happens with probability \((1-p)^n\)), in which case \(S_n = 0\) and \(\hat p = 0\).
So instead of requiring that \(|\hat p - p| \le \epsilon\) with absolute certainty, we relax our requirement and only demand that \(|\hat p - p| \le \epsilon\) with confidence \(\delta\), namely, \({\mathbb{P}}[|\hat p - p| \le \epsilon] \ge 1-\delta\). This means there is a small probability \(\delta\) that we make an error of more than \(\epsilon\), but with high probability (at least \(1-\delta\)) our estimate is very close to \(p\). Now we can state our result: to guarantee that \({\mathbb{P}}[|\hat p - p| \le \epsilon] \ge 1-\delta\), it suffices to toss the coin \(n\) times where \[n \ge \frac{1}{4\epsilon^2 \delta}.\]
To prove such a result we use the tool called Chebyshev’s Inequality, which provides a quantitative bound on how far away a random variable is from its expected value.
Markov’s Inequality
Before going to Chebyshev’s inequality, we first state the following simpler bound, which applies only to non-negative random variables (i.e., r.v.’s which take only values \(\ge 0\)).
Theorem 1 (Markov's Inequality)
For a non-negative random variable \(X\) with expectation \({\mathbb{E}}[X]=\mu\), and any \(\alpha>0\), \[{\mathbb{P}}[X\ge\alpha]\le{{{\mathbb{E}}[X]}\over\alpha}.\]
Proof. From the definition of expectation, we have \[\begin{aligned} {\mathbb{E}}[X] &=\sum_a a\times{\mathbb{P}}[X=a]\cr &\ge \sum_{a\ge\alpha} a\times{\mathbb{P}}[X=a]\cr &\ge \alpha\sum_{a\ge\alpha} {\mathbb{P}}[X=a]\cr &=\alpha{\mathbb{P}}[X\ge\alpha]. \end{aligned}\] Rearranging the inequality gives us the desired result. The crucial step here is the second line, where we have used the fact that \(X\) takes on only non-negative values. (Why is this step not valid otherwise?) \(\square\)
There is an intuitive way of understanding Markov’s inequality through an analogy of a seesaw. Imagine that the distribution of a non-negative random variable \(X\) is resting on a fulcrum, \(\mu = {\mathbb{E}}[X]\). We are trying to find an upper bound on the percentage of the distribution which lies beyond \(k \mu\), i.e., \({\mathbb{P}}[X \ge k \mu]\). In other words, we seek to add as much weight \(m_2\) as possible on the seesaw at \(k \mu\) while minimizing the effect it has on the seesaw’s balance. This weight will represent the upper bound we are searching for. To minimize the weight’s effect, we must imagine that the weight of the distribution which lies beyond \(k \mu\) is concentrated at exactly \(k \mu\). However, to keep things stable and maximize the weight at \(k \mu\), we must add another weight \(m_1\) as far left to the fulcrum as we can so that \(m_2\) is as large as it can be. The farthest we can go to the left is \(0\), since \(X\) is assumed to be non-negative. Moreover, the two weights \(m_1\) and \(m_2\) must add up to \(1\), since they represent the area under the distribution curve:
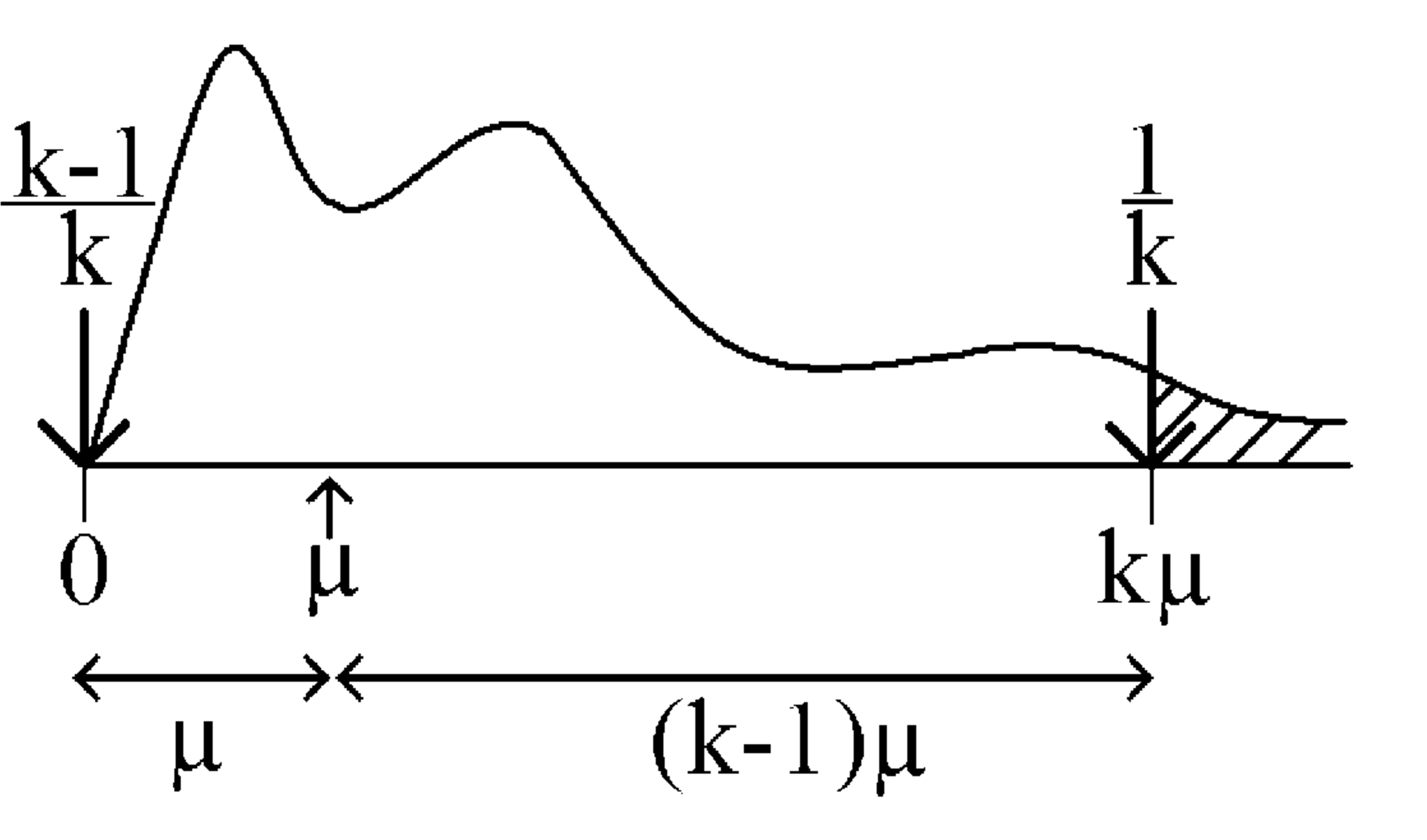
Figure 1: Markov’s inequality interpreted as balancing a seesaw.
Since the lever arms are in the ratio \(k-1\) to \(1\), a unit weight at \(k \mu\) balances \(k-1\) units of weight at \(0\). So the weights should be \((k-1)/k\) at \(0\) and \(1/k\) at \(k\mu\), which is exactly Markov’s bound with \(\alpha = k\mu\).
Chebyshev’s Inequality
We have seen that, intuitively, the variance (or, more correctly the standard deviation) is a measure of “spread,” or deviation from the mean. We can now make this intuition quantitatively precise:
Theorem 2 (Chebyshev's Inequality)
For a random variable \(X\) with expectation \({\mathbb{E}}[X]=\mu\), and for any \(\alpha>0\), \[{\mathbb{P}}[|X-\mu|\ge\alpha] \le {{{\operatorname{var}}(X)}\over{\alpha^2}}.\]
Proof. Define the random variable \(Y=(X-\mu)^2\). Note that \({\mathbb{E}}[Y]={\mathbb{E}}[(X-\mu)^2]={\operatorname{var}}(X)\). Also, notice that the event that we are interested in, \(|X-\mu| \ge \alpha\), is exactly the same as the event \(Y = (X-\mu)^2 \ge \alpha^2\). Therefore, \({\mathbb{P}}[|X-\mu| \ge \alpha] = {\mathbb{P}}[Y \ge \alpha^2]\). Moreover, \(Y\) is obviously non-negative, so we can apply Markov’s inequality to it to get \[{\mathbb{P}}[Y\ge\alpha^2] \le {{{\mathbb{E}}[Y]}\over{\alpha^2}} = {{{\operatorname{var}}(X)}\over{\alpha^2}}.\] This completes the proof. \(\square\)
Let’s pause to consider what Chebyshev’s inequality says. It tells us that the probability of any given deviation, \(\alpha\), from the mean, either above it or below it (note the absolute value sign), is at most \({\operatorname{var}}(X)/\alpha^2\). As expected, this deviation probability will be small if the variance is small. An immediate corollary of Chebyshev’s inequality is the following:
Corollary 1
For a random variable \(X\) with expectation \({\mathbb{E}}[X]=\mu\), and standard deviation \(\sigma=\sqrt{{\operatorname{var}}(X)}\), \[{\mathbb{P}}[|X-\mu|\ge\beta\sigma] \le {1\over{\beta^2}}.\]
Proof. Plug \(\alpha=\beta\sigma\) into Chebyshev’s inequality. \(\square\)
So, for example, we see that the probability of deviating from the mean by more than (say) two standard deviations on either side is at most \(1/4\). In this sense, the standard deviation is a good working definition of the “width” or “spread” of a distribution.
In some special cases it is possible to get tighter bounds on the probability of deviations from the mean. However, for general random variables Chebyshev’s inequality is essentially the only tool. Its power derives from the fact that it can be applied to any random variable.
Example: Estimating the Bias of a Coin
Let us go back to our motivating example of estimating the bias of a coin. Recall that we have a coin of unknown bias \(p\), and our estimate of \(p\) is \(\hat p = S_n/n\) where \(S_n\) is the number of Heads in \(n\) coin tosses.
As usual, we will find it helpful to write \(S_n = X_1 + \cdots + X_n\), where \(X_i = 1\) is the \(i\)-th coin toss comes up Heads and \(X_i = 0\) otherwise, and the random variables \(X_1,\dots,X_n\) are mutually independent. Then \({\mathbb{E}}[X_i] = {\mathbb{P}}[X_i = 1] = p\), so by linearity of expectation, \[{\mathbb{E}}[\hat p] = {\mathbb{E}}\!\left[\frac{1}{n} S_n\right] = \frac{1}{n} \sum_{i=1}^n {\mathbb{E}}[X_i] = p.\] What about the variance of \(\hat p\)? Note that since the \(X_i\)’s are independent, the variance of \(S_n = \sum_{i=1}^n X_i\) is equal to the sum of the variances: \[{\operatorname{var}}(\hat p) = {\operatorname{var}}\!\left(\frac{1}{n} S_n\right) = \frac{1}{n^2} {\operatorname{var}}(S_n) = \frac{1}{n^2} \sum_{i=1}^n {\operatorname{var}}(X_i) = \frac{\sigma^2}{n},\] where we have written \(\sigma^2\) for the variance of each of the \(X_i\).
So we see that the variance of \(\hat{p}\) decreases linearly with \(n\). This fact ensures that, as we take larger and larger sample sizes \(n\), the probability that we deviate much from the expectation \(p\) gets smaller and smaller.
Let’s now use Chebyshev’s inequality to figure out how large \(n\) has to be to ensure a specified accuracy in our estimate of the true bias \(p\). As we discussed in the beginning of this note, a natural way to measure this is for us to specify two parameters, \(\epsilon\) and \(\delta\), both in the range \((0,1)\). The parameter \(\epsilon\) controls the error we are prepared to tolerate in our estimate, and \(\delta\) controls the confidence we want to have in our estimate.
Applying Chebyshev’s inequality, we have \[{\mathbb{P}}[|\hat p-p|\ge \epsilon] \le \frac{{\operatorname{var}}(\hat p)}{\epsilon^2} = \frac{\sigma^2}{n\epsilon^2}.\] To make this less than the desired value \(\delta\), we need to set \[ n\ge {{\sigma^2}\over{\epsilon^2\delta}}.\](1) Now recall that \(\sigma^2={\operatorname{var}}(X_i)\) is the variance of a single sample \(X_i\). So, since \(X_i\) is an indicator random variable with \({\mathbb{P}}[X_i = 1] = p\), we have \(\sigma^2 = p(1-p)\), and Equation 1 becomes \[ n\ge {{p(1-p)}\over {\epsilon^2\delta}}.\](2) Since \(p(1-p)\) is takes on its maximum value for \(p=1/2\), we can conclude that it is sufficient to choose \(n\) such that: \[\label{eq3} n\ge {{1}\over {4\epsilon^2\delta}},\] as we claimed earlier.
For example, plugging in \(\epsilon=0.1\) and \(\delta=0.05\), we see that a sample size of \(n=500\) is sufficient to get an estimate \(\hat p\) that is accurate to within an error of \(0.1\) with probability at least \(95\%\).
As a concrete example, consider the problem of estimating the proportion \(p\) of Democrats in the U.S. population, by taking a small random sample. We can model this as the problem of estimating the bias of a coin above, where each coin toss corresponds to a person that we select randomly from the entire population. Our calculation above shows that to get an estimate \(\hat p\) that is accurate to within an error of \(0.1\) with probability at least \(95\%\), it suffices to sample \(n = 500\) people. In particular, notice that the size of the sample is independent of the total size of the population! This is how polls can accurately estimate quantities of interest for a population of several hundred million while sampling only a very small number of people.
Estimating a General Expectation
What if we wanted to estimate something a little more complex than the bias of a coin? For example, suppose we want to estimate the average wealth of people in the U.S. We can model this as the problem of estimating the expected value of an unknown probability distribution. Then we can use exactly the same scheme as before, except that now we sample the random variables \(X_1,X_2,\dots,X_n\) independently from our unknown distribution. Clearly \({\mathbb{E}}[X_i]=\mu\), the expected value that we are trying to estimate. Our estimate of \(\mu\) will be \(\hat \mu= n^{-1} \sum_{i=1}^n X_i\), for a suitably chosen sample size \(n\).
Following the same calculation as before, we have \({\mathbb{E}}[\hat \mu]=\mu\) and \({\operatorname{var}}(\hat \mu)= \sigma^2/n\), where \(\sigma^2={\operatorname{var}}(X_i)\) is the variance of the \(X_i\). (Recall that the only facts we used about the \(X_i\) was that they were independent and had the same distribution — actually the same expectation and variance would be enough: why?) This time, however, since we do not have any a priori bound on the mean \(\mu\), it makes more sense to let \(\epsilon\) be the relative error, i.e., we wish to find an estimate \(\hat \mu\) that is within an additive error of \(\epsilon\mu\): \[{\mathbb{P}}[|\hat \mu-\mu|\ge \epsilon\mu] \le \delta.\] Using Equation 1, but substituting \(\epsilon\mu\) in place of \(\epsilon\), it is enough for the sample size \(n\) to satisfy \[ n\ge {{\sigma^2}\over{\mu^2}}\times{1\over{\epsilon^2\delta}}.\](3) Here \(\epsilon\) and \(\delta\) are the desired relative error and confidence respectively. Now of course we don’t know the other two quantities, \(\mu\) and \(\sigma^2\), appearing in Equation 3. In practice, we would use a lower bound on \(\mu\) and an upper bound on \(\sigma^2\) (just as we used an upper bound on \(p(1-p)\) in the coin tossing problem). Plugging these bounds into equation will ensure that our sample size is large enough.
For example, in the average wealth problem we could probably safely take \(\mu\) to be at least (say) $20k (probably more). However, the existence of very wealthy people such as Bill Gates means that we would need to take a very high value for the variance \(\sigma^2\). Indeed, if there is at least one individual with wealth $50 billion, then assuming a relatively small value of \(\mu\) means that the variance must be at least about \((50\times 10^9)^2 / (250\times 10^6) = 10^{13}\). There is really no way around this problem with simple uniform sampling: the uneven distribution of wealth means that the variance is inherently very large, and we will need a huge number of samples before we are likely to find anybody who is immensely wealthy. But if we don’t include such people in our sample, then our estimate will be way too low.
The Law of Large Numbers
The estimation method we used in the previous sections is based on a principle that we accept as part of everyday life: namely, the Law of Large Numbers (LLN). This asserts that, if we observe some random variable many times, and take the average of the observations, then this average will converge to a single value, which is of course the expectation of the random variable. In other words, averaging tends to smooth out any large fluctuations, and the more averaging we do the better the smoothing.
Theorem 3 (Law of Large Numbers)
Let \(X_1,X_2,\ldots,X_n\) be i.i.d. random variables with common expectation \(\mu={\mathbb{E}}[X_i]\). Define \(A_n= n^{-1} \sum_{i=1}^n X_i\). Then for any \(\alpha>0\), we have \[{\mathbb{P}}\left[|A_n-\mu|\ge\alpha\right] \to 0 \qquad \text{as $n\to\infty$}.\]
Proof. Let \({\operatorname{var}}(X_i)=\sigma^2\) be the common variance of the r.v.’s; we assume that \(\sigma^2\) is finite.1 With this (relatively mild) assumption, the LLN is an immediate consequence of Chebyshev’s inequality. For, as we have seen above, \({\mathbb{E}}[A_n]=\mu\) and \({\operatorname{var}}(A_n)= \sigma^2/n\), so by Chebyshev we have \[{\mathbb{P}}\left[|A_n-\mu|\ge\alpha\right] \le \frac{{\operatorname{var}}(A_n)}{\alpha^2} = \frac{\sigma^2}{n\alpha^2} \to 0 \qquad\text{as $n\to\infty$}.\] This completes the proof. \(\square\)
Notice that the LLN says that the probability of any deviation \(\alpha\) from the mean, however small, tends to zero as the number of observations \(n\) in our average tends to infinity. Thus by taking \(n\) large enough, we can make the probability of any given deviation as small as we like.
If \(\sigma^2\) is not finite, the LLN still holds but the proof is much trickier.↩